[Keras筆記]用ImageDataGenerator訓練大型資料集需要注意的幾件事
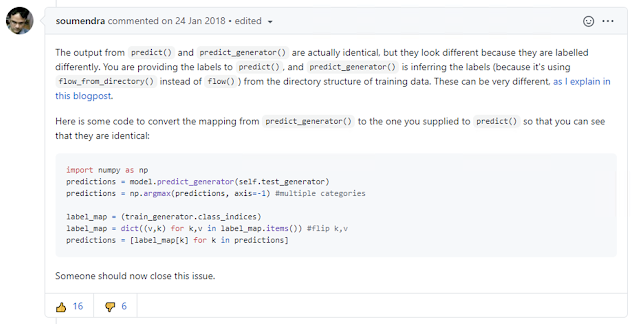
以前訓練小資料集都是用model.fit(X,Y) 評估訓練過後的模型用model.evaluate(...) 測試單張圖片則是用model.predict(image) 而因為以前學的時候,只是用小型資料集做練習,所以我們使用的標籤都會是自己定義的indices 現在常會接觸到大型資料集,所以訓練方法會變成: 訓練模型的時候用model.fit_generator() 評估模型的時候用scores = model.evaluate_generator() #這個會回傳一個list,像這邊score是一個list,會有兩個數字,第一個數字我記得是代表loss,第二個數字是準確度,範圍在0~1.0之間,所以要再自己準換成百分比。 evaluate_generator()就是由照片所屬的資料夾名稱下去推斷照片預測的是不是屬於正確的類別,也就是有正確答案作為參考,所以才算得出準確度來(scores[1])。 用模型去做批次照片的預測機率用scores = model.predict_generator() #假如有10個資料夾(分10類),每個資料夾有3張照片要做測試,則scores就是一個[30, 10]的array型態。 而要用訓練完的模型去做「單張」照片的預測,有兩種方法可以使用: (1) model.predict(image) #會回傳一個numpy array,每個數值代表預測出每個類別的機率。 (2) model.predict_classes(image) #會回傳預測出機率最高的類別「索引」。 這裡就有趣了,這邊的每個類別的機率分佈跟「索引」代表的是「generator.class_indices」所推斷出來的索引,而不是按照檔案總管裡面資料夾的排序當作索引。 我會發現這個問題是因為我在交叉使用model.predict_generator()跟model.predict()時,機率的分佈跟預測出來的類別有很大的不一樣,一開始還以為是訓練出問題,原來只是generator推斷的類別索引順序跟我想的不一樣,或是說以前用model.predict()的概念不同罷了(汗... 解決辦法: 參考網路上別人的發問,要使用model.predict_classes()找出測試的對應類別機率和預測的類別,只要做個dictionary做簡單的轉換就好。 [標籤轉換]ht...